

お疲れ様です。M.Kです。
今回は普通に「文字化け」についての話です。
わかりやすさ優先のため、全体的にざっくりとした説明です。
それではとりあえず、サクッと文字化けテキストを作ってみましょう。
①メモ帳を開きます。
②好きな言葉を入力します。
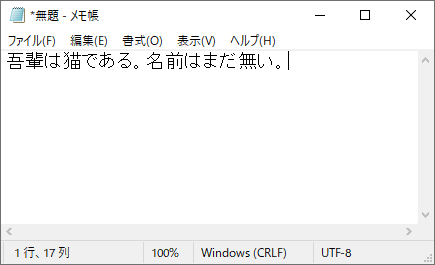
③保存します。この時、文字コードに「UTF-8」を設定します。
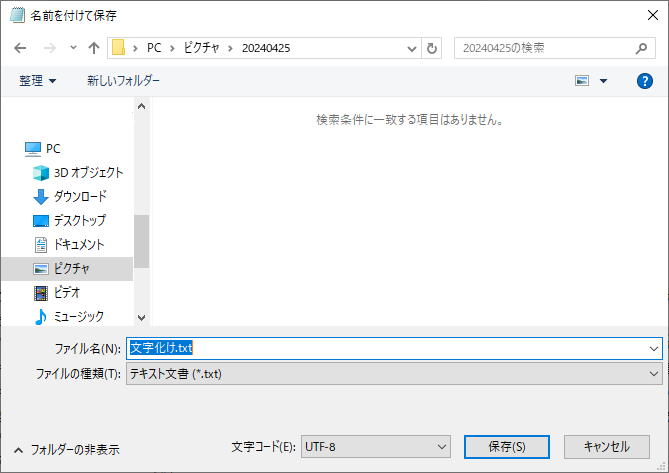
④メモ帳の上のメニューから「ファイル」→「開く」を選択します。
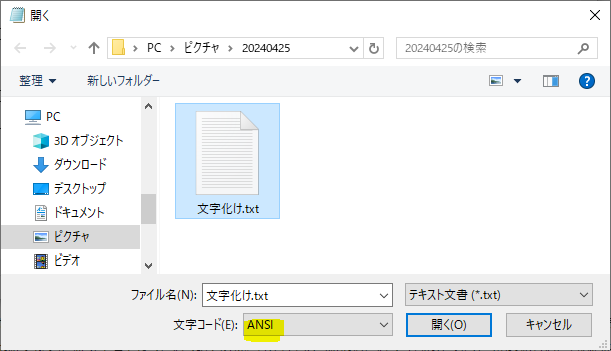
⑤先ほど開いたファイルを選択し、文字コードを今度は「ANSI」と選択します。
⑥テキストの中身が文字化けで表示されました。
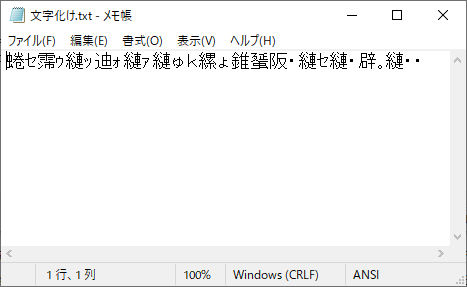
文字化けの原因は、保存した文字コードの違いです。
今回は、「UTF-8」で保存したファイルを「Shift_JIS」(メモ帳では”ANSI”という選択肢になっています)で開いたのが原因です。
「吾輩は猫である。名前はまだ無い。」
↓
「蜷セ霈ゥ縺ッ迪ォ縺ァ縺ゅk縲ょ錐蜑阪・縺セ縺辟。縺・・」
もちろん⑤でUTF-8で開けば、保存した文字のまま問題なく表示されます。
なぜこのような謎文字列に変換されたのかをざっくりと解説します。
まず、PCで表示される文字の正体は、厳密には”010101…”という値です。
文字コードという、『○○の値=あ』といったようなルールがあり、そのルールに基づいて値が変換され、PCに表示されるのです。
この文字コードには様々な種類があり、その中に、UTF-8やShift_JISがあります。
この文字コードの適用誤りで発生するのが文字化けです。
試しに文字列を、UTF-8での文字列に変換される前の、バイナリ値(16進数)に戻してみます。
「吾輩は猫である。名前はまだ無い。」
↓
「E590BEE8BCA9E381AFE78CABE381A7E38182E3828BE38082E5908DE5898DE381AFE381BEE381A0E784A1E38184E38082」
UTF-8での「吾輩」という文字は、元々は
「E5 90 BE」←「吾」
「E8 BC A9」←「輩」
…
という値だったということです。
ところで、このバイナリ値を、Shift_JISのルールに従った変換にしてみると、
「E5 90」→「蜷」
「BE」→「セ」
「E8 BC」→「霈」
…
と、同じバイナリ値から、まったく違った文字に変換されます。
これが文字化け後の謎の文字列の正体です。
ちなみに、
「蜷」は「にな」と読み、細い巻貝の総称。
「霈」は「おおあめ」と読み、そのまま大雨のことだそうです。
文字化けで初めて出会う漢字があるかもしれません。








